LockPicking - The AI Version
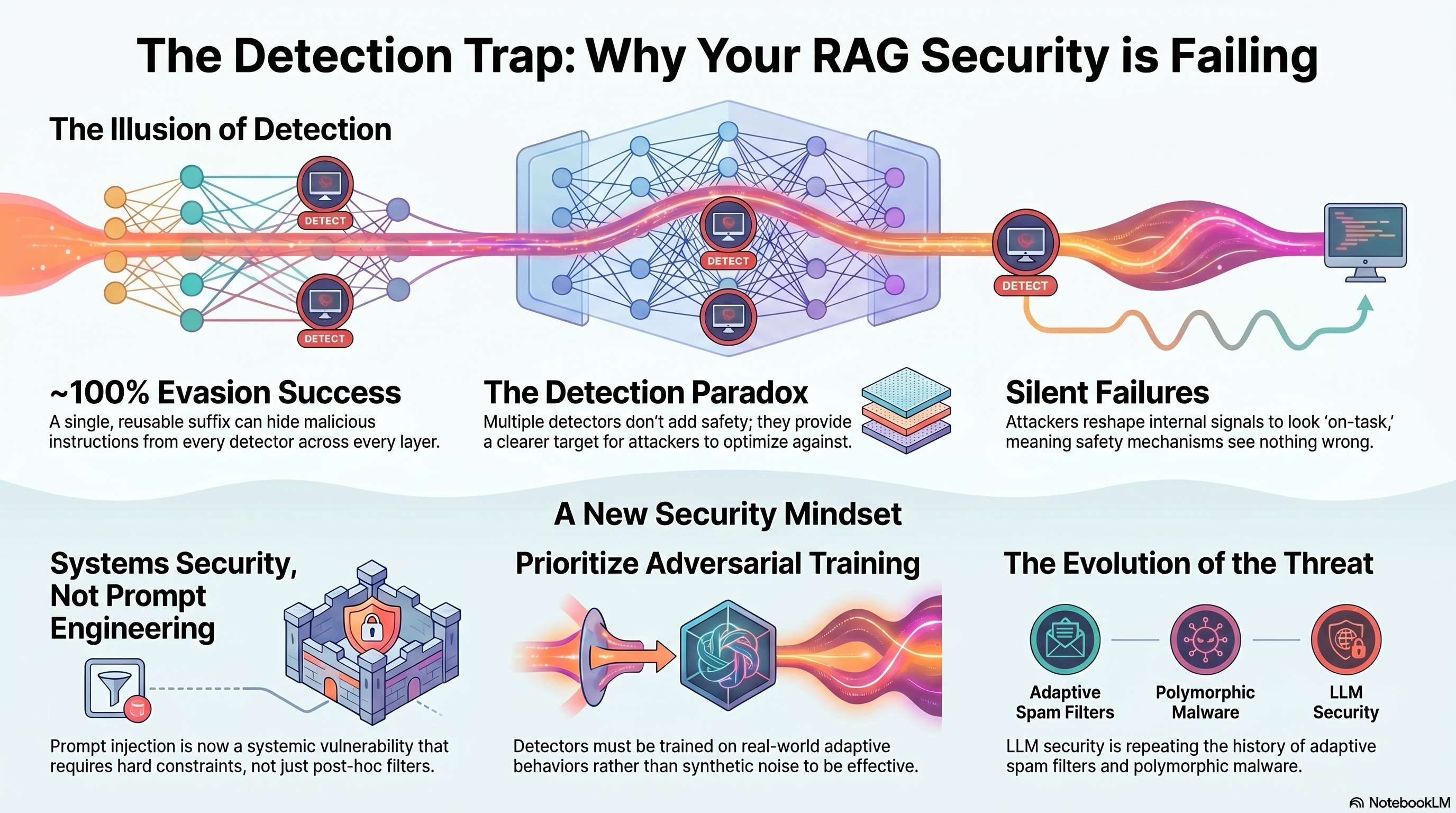
A new paper demonstrates that one of the most promising defenses against prompt injection can be almost perfectly bypassed.
- Not by clever wording.
- Not by social engineering.
- By adapting to the defense itself.
The existing defense idea is elegant and widely appealing: Watch how an LLM’s internal behavior changes when it reads retrieved text
- Flag “task drift” when injected instructions appear
- Monitor multiple layers and use majority voting for safety This wasn’t a hacky filter. And it worked - until the attacker adapted.
What the paper shows An adaptive attacker can generate one short, reusable suffix that:
- Gets appended to injected prompts
- Leaves the malicious instruction fully intact Results in
- Every detector, across every layer, to say “this looks fine”
- Achieves ~99–100% evasion rates, even with majority voting
One suffix !
The suffix doesn’t persuade the model in any human sense. Instead, it subtly reshapes the model’s internal signals so they resemble:
- Normal
- Harmless
- On-task behavior
The detectors never see anything “off.”
Why? Because the attacker explicitly optimizes the suffix to avoid exactly what the detectors are looking for.
Multiple detectors don’t add safety here — they just give the attacker a clearer target.
This flips a core assumption on its head: Detection itself becomes the attack surface.
If the safety mechanism is:
- Observable
- Consistent
- And reacts predictably to inputs Then an attacker can learn how to stay just inside its comfort zone.
At that point:
- Monitoring ≠ protection
- “We’ll just detect drift” ≠ security
- And failures become silent by default
We’ve seen this pattern before:
- Spam filters vs adaptive spammers
- Malware signatures vs polymorphic malware
- Content moderation vs coordinated abuse LLMs aren’t special here.
The way forward:
- Training detectors on synthetic noise doesn’t help much
- Training them on real adversarial behaviors helps a lot
In other words: Defenses improve only when they’re trained on how attackers actually adapt.
Key Takeaway Prompt injection is a systems security problem.
- Detectors can be learned
- Learned systems can be bypassed
- And “more detectors” doesn’t equal “more safety”
Read the paper here: Bypassing Prompt Injection Detectors through Evasive Injections
#AI #Security #RAG #WomenInTech #LLMs #PromptInjection