The Surprise Vector
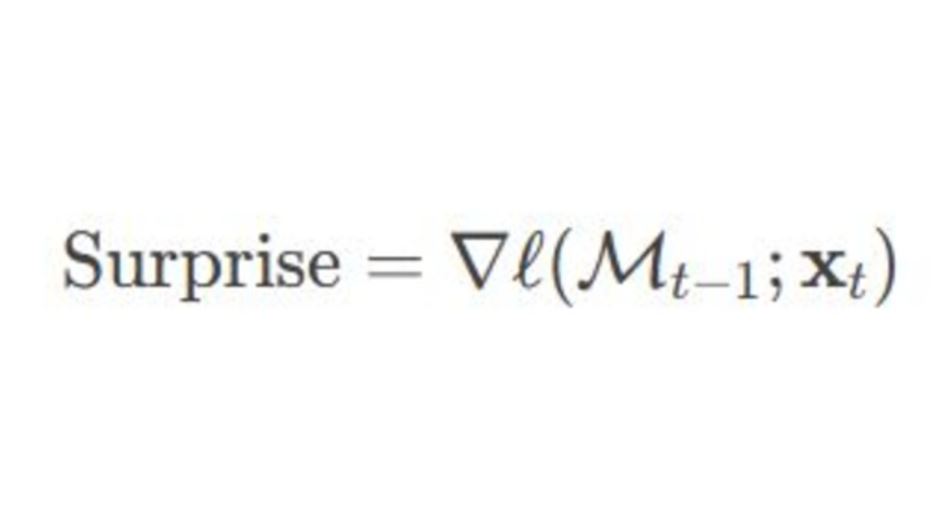
In case you ever wondered about the formula for ‘Surprise’ in neural networks – this paper has quantified it.
In fact, I am surprised the title of the paper does not include this word; it would make it more memorable! However, it does not need to rely on clickbait for attention.
🔑 Key points:
- The Surprise Metric
- Forgetting Mechanism
- Memorization at Test Time
Breaking it down:
1️⃣ The Surprise Metric
🧠 The human brain remembers surprising and unexpected events because they often carry valuable or unique information. Taking inspiration from this, Titan’s memory module incorporates a surprise metric (data that might be out-of-distribution or unexpected data). To create a balance between recent and historical events of significance, there are two types of surprise that are considered:
a. Momentary Surprise: Measures the novelty of the current input, capturing immediate changes.
b. Past Surprise: Encodes the surprise from previous time steps as momentum, helping track trends over time.
By focusing on “surprising” inputs, Titans prioritize significant events over repetitive or less relevant information.
💡
Gradient Rethink: While traditional models minimize large gradients to smooth errors, Titans’ surprise-based mechanism does not equate large gradients directly with “errors”.
Instead, it considers that a large gradient indicates the input differs significantly from previously seen data, making it more “surprising”. Titans leverage these as signals of surprise — prioritizing updates for novel data rather than static optimization.
2️⃣ Forgetting Mechanism ⏳ If the human brain encounters the same surprise many times, it is no longer a novelty.
In the same vein, Titan’s Forgetting Mechanism forgets unimportant information, allowing the memory to focus on retaining persistent patterns while discarding transient or irrelevant spikes. It causes old surprises to fade over time.
3️⃣ Memorization at Test Time 💡 From a business perspective, I think this is the most important result – real-time memorization means there is conceptually no retraining required. With its dynamic adaptation and ability to handle massive contexts (2M+ tokens), it is highly effective for long-context tasks that require continuous adaptation, long-term dependency resolution, and handling novel data in ever-changing environments.
Titan Variants
🖥️ The architecture incorporates parallel training and avoids the quadratic computational cost of the transformer model.
There are three variants of Titan architecture in the paper:
- Memory as Context (akin to a three-part memory system)
- Memory as a Gate (behaves like a filter)
- Memory as a Layer (compresses information)
Results
🏆 Titans excelled in needle-in-haystack retrieval, time series tasks, genomic sequencing, etc.
Ablation Study
📊 The ablation study on the different architectural choices indicates that all components are critical to Titans’ superior performance. The top two contributions come from Weight Decay (Forgetting Mechanism) and Momentum (integrating past surprise effectively).
A few business use cases
- Real-time fraud detection with Anomaly and Pattern Recognition
- Real-time adaptive response to cyber threats
- Detecting niche interests in streaming platforms
- Personalized treatment plans based on long-term medical history
- Early warning for critical health events like arrhythmias
Some additional thoughts
- Memory Poisoning: Considering the architecture can adapt its memory in real-time, how would it handle data/memory poisoning? For example, an attacker could flood the model with artificially surprising and malicious inputs, causing the memory to become saturated with harmful or irrelevant information.
- Guardrails: Where could guardrails be added? In the persistent memory layer, which encodes knowledge about a task?
In conclusion
🚀 This is a fascinating paper, and it promises to be a game-changer for neural architectures and their applications. I am wondering what is next in this space? A memory palace within a neural architecture?
To read the paper - Titans: Learning to Memorize at Test Time
#NeuralNetworks #AI #MachineLearning #DeepLearning #SurpriseMetric #MemoryModels #Innovation #TechTrends #BusinessUseCases #AI #CyberSecurity #FutureTech #WomenWhoCode #WomenInTech #LeanIn #AIResearch #WomenInTech #WomenInSTEM #WomenTechmakers